Improving in chess is hard. I built the world’s most human-like chess AI to help me.
13 minutes
Oct 31, 2025
Getting better at chess is really hard. My theory is that it’s at least partially because of the feedback lag. Imagine learning to play the violin, but you have to play each song with earplugs in, then listen to the recording after. This is roughly what chess learning feels like, outside of focused drills. You play a game, ignorant of which moves are good and bad, then you get feedback from the computer at the end of the game – way past the point where you made the move. I don’t think this is compatible with how humans learn, generally.
So I’d like to get feedback as I play. Are my moves good, what are my chances of winning, did I miss a trick somewhere, etc. In matches against humans, this is generally referred to as “cheating” that will get you “banned from the platform”. So we need a computer opponent.
Stockfish is around, and it’s the best engine in the world, so why not just play a game against it? Well, you have a few options with Stockfish:
- Play a fair game and get crushed mercilessly
- Heavily handicap it with limited search, where it will mostly still play like a god, then hang an easy tactic every now and then
- Play with piece-odds, like taking away its queen – now you’re playing against an opponent that doesn’t play like a human, in a game that doesn’t follow the standard setup of chess
So I want to play a game of chess against an opponent that plays much like my real opponents online, and get live feedback on my moves.
Setting a ridiculous target
What we want here is a human-like “bot”. An engine that, instead of trying to play the best moves, attempts to play like a human. Projects like Maia have sprung up to serve this niche, as well as Chessiverse, Noctie, etc.
Maia-2 is the gold standard here. When given a player’s rating and a chess position, Maia can predict the move they’ll make 53% of the time. Note that the theoretical upper bound is nowhere close to 100% – I’d wager it’s something like 60%. To illustrate that, even if you give the same human the same position on two different days, they have good odds of playing something different.
So, with no ML experience, I’m going to set out to beat Maia-2 at its own game. There’s no reason to expect success here, only that when I encounter a problem I really want to solve, I can bash my head against it more than most people.
Let’s throw transformers at it
Maia-2 uses a convolutional neural net. If you look that up you’ll get a bunch of matrix math, but basically the model starts out looking at 3x3 areas of the chessboard, and as the layers get deeper this “receptive field” expands outward.
But convolutional nets are, like, so last year. I want to use what all the cool kids are using – transformers. If that em-dash made you suspicious, you’re thinking of a transformer model.
I’m only sort of joking, there’s a real reason here too. Convolutional nets are way better at local relationships than far-reaching ones. In chess, a queen on a1 is attacking a2 (one square away) just as much as it’s attacking h8 (7 squares away). Convolutional nets would naturally have some bias towards local patterns. Transformers, on the other hand, don’t care about how close tokens (squares) are to each other. Any token (square) can “pay attention” to any other token (square), with equal importance. So I had a hunch they might have a higher capacity.
When I say “token”, you can mentally replace it with “square”, and vice-versa. The input to the model is just the 64 squares of the chessboard, represented as tokens.
Transformers have no concept of position
Turns out, transformers, by default, do not have any sense of where a token is in the sequence, or how they relate to any other token. If someone took the pieces from a chess position, put them in a bag, and asked you to make the move based on the contents of the bag, you probably wouldn’t be playing great chess.

There are a ton of ways to make transformers learn about the position of pieces. RoPe (rotary position embedding) is the most popular variant for LLMs (if you want to break your brain, try to understand how RoPe works, it’s still just wizardry to me). Then there are absolute position embeddings, which is a way of specifying what square a piece is on. There’s Shaw relative attention… the list goes on and there’s variants of these cropping up all the time.
I’ve experimented with this a lot. This is one of those black-box ML things where you throw shit architecture at the wall and see what sticks. I don’t think this is a failing of me as a machine-learning noob either – there’s a ton of cases like this in ML. The gold standard in ML is literally an “ablation test”, where you just turn some things off and see how well the model learns in a run. It feels like we’re in the medieval ages where they hadn’t discovered real structural engineering yet, so they just built bridges and cathedrals and hoped they wouldn’t collapse.
Anyway, in the end I settled on absolute position embeddings which tells the model exactly “this piece is on b2”, and Shaw relative attention, which lets the model learn things like “if this piece is a bishop, I should look along the diagonals”. These “rules” can get as arbitrary as the model wants, like “if there’s a queen on this square which is pinned behind a pawn, there are knights remaining, and we’re low on time, then attend to the squares which are not attacked by a knight.” Of course they’re not really rules, they’re a mad mess of matrix multiplication, but if you somehow managed to work backwards from the attention layers to the embeddings to the tokens, then you’d find things like this.
Living under the oppressive regime of AdamW
When training a model, you have to pick an optimizer. A model is just a ton of weights (numbers), and after each training iteration, you have to figure out which direction those weights should go. You run your batch, find the direction and magnitude (the gradient loss curve) that all of these weights should move in to reduce your loss, then feed that into an optimizer to figure out how it should calculate the new weights.
Optimizers go in and out of fashion, but the latest and greatest for transformers is AdamW. The math is beyond me, so I won’t embarrass myself and waste your time by trying to explain. I understand it’s doing some really clever things with “momentum” and “adaptive learning”, and I’m really proud of Adam W. for all that.
Adam W. is a menace to society large weights. Models work best when their weights are kept in reasonable ranges, and so Adam W. will artificially adjust the loss value at each iteration, to add a penalty term for large weights. Generally great, still really proud of you Adam, etc. But there are some pieces of a model’s architecture that should not be subject to this weight decay. Stuff like embeddings, scale multipliers, biases, should be allowed to grow large without penalizing the model.
I had to discover this for myself by individually monitoring tensor norms and thinking through, from first principles, what scale these tensors should take and why they’re not doing that. I did enough research on optimizers that I would have expected to come across something this impactful organically. I think it’s one of those things that you only run into when you get deep enough, and a lot of ML learning material out there is pretty shallow.
Throwing a ton of compute at it
The bitter lesson is that the only thing that has consistently driven long-term progress in AI is leveraging ever-increasing computation and data, enabled by Moore’s Law — not human-crafted features, domain knowledge, or clever algorithms.
Richard Sutton
I’ve got a really nice computer. An M4 Max with 128GB of RAM is a powerful setup. But to train a large model with this, would be like carving an ice sculpture with a toothpick. So I brought in the big guns. An NVIDIA B200 has 64 times more compute and 16 times the memory bandwidth. Each one can process roughly 50 times more training data than an M4 Max.
I rented eight of them.
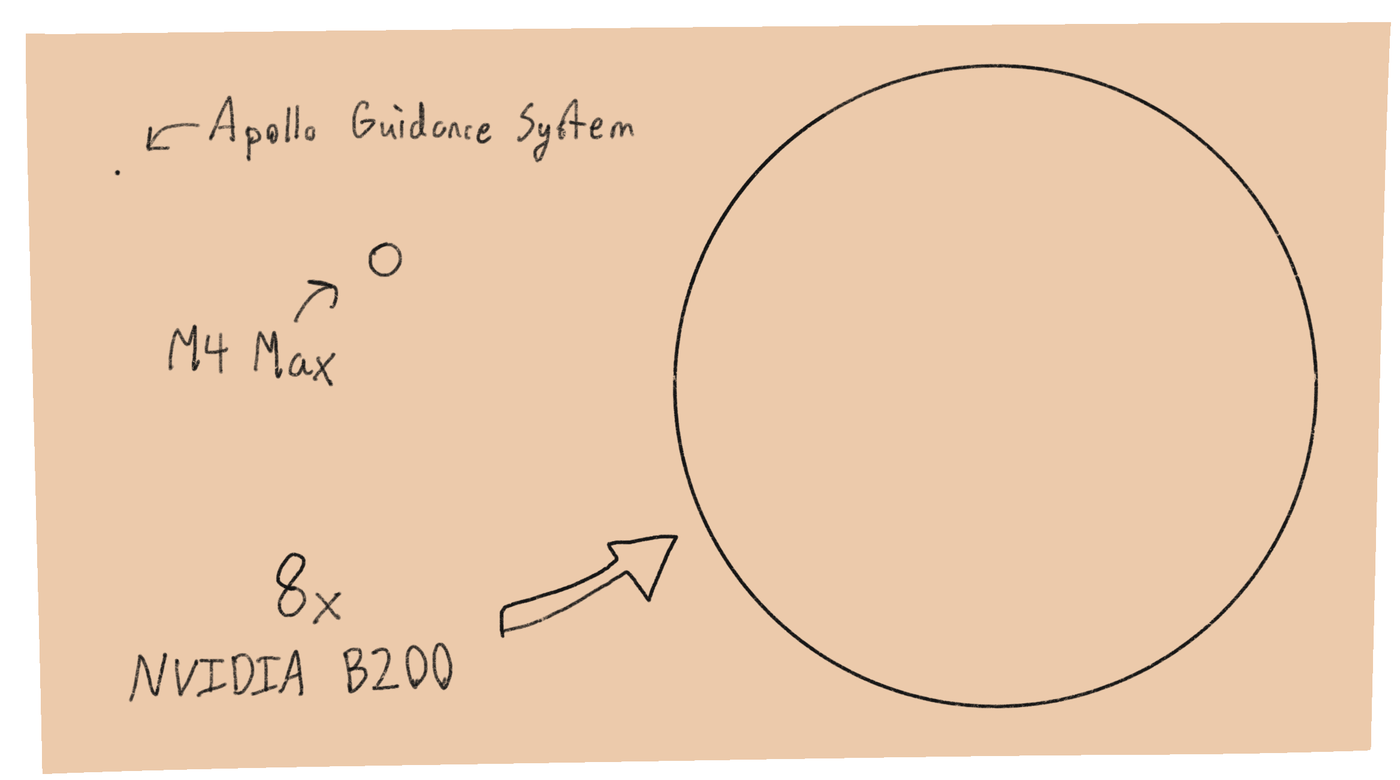
That’s just a touch over 18 petaflops. The first computer to reach 1 teraflop was the ASCI Red in 1997. It cost $55 million dollars and was the size of a tennis court. If you filled up central park with 18,000 of those, you’d be close in power to my setup.
I rented this mind-bending quantity of compute for $30 per hour. To train my stupid little chess project. Computers are incredible.
Feature engineering
A token in a machine learning model is composed of features. Features are just numbers that represent that piece of data. In our case, a token (square) can encode any sort of chess information that a player might take into account – is there a piece on this square, is it pinned, how many legal moves does it have, who is defending it, what pieces are close to it, is it a passed pawn, etc.
I found this piece of the project to be a really interesting bit of introspection. When there was a position where the model wasn’t learning the human-like move, I could sort of analyze my own intuitions and find why it was an intuitive move for me but not the model. Each square has about 80 features in the final model, but let’s cover some of the more interesting bits.
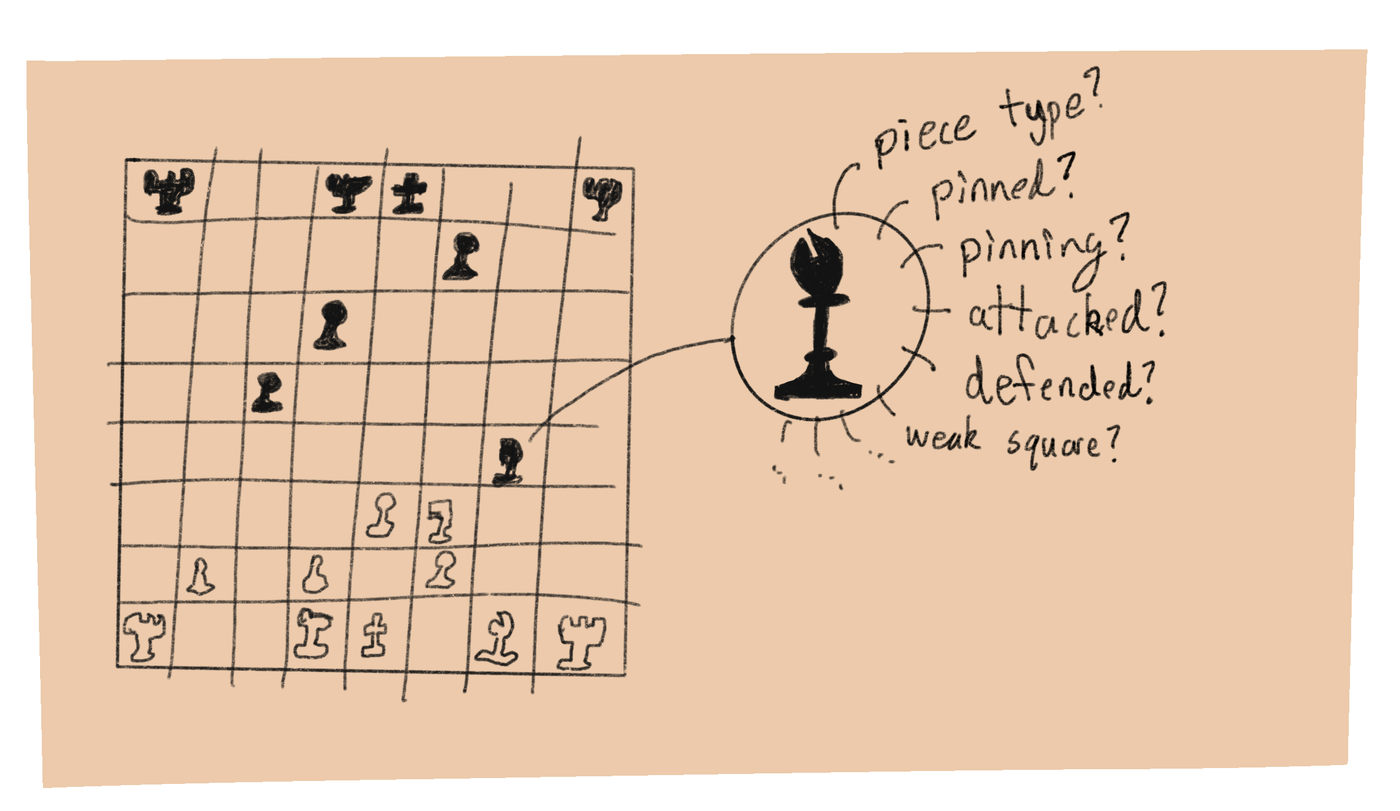
Pins
You don’t realize how important pins are in higher-level chess, until you train a model that has no conception of them. When a pin is on the board, it almost always deserves at least a small portion of your working memory, and consideration in making your next move. Pins are hard for a transformer model to find; it has to waste a lot of compute and layers just finding all the relationships. It’s also bound to be somewhat lossy, so it’s ideal if we can just encode pin relationships directly.
Unfortunately this is one of those pieces that doesn’t have a clean translation to features. Features are numbers, and how do you translate something like “the bishop is pinning a knight on c3 to the king on e1”? You have to break it into mostly one-hot flags (when ML people say one-hot, they mean binary, don’t ask me why), like isPinned, isPinning, isBehindPin, isAbsolutePin (pinned to a king), etc etc.
Square control
Determining who has control of a square in chess is a pretty interesting problem. Is it the person with the most material aiming at that square? A square defended by pawn, and attacked by both knights, a queen, both rooks, and a bishop, is still “controlled” by the side with the pawn defending it. Of course there are tactical possibilities of sacrificing pieces, but the square is safe for one side to put a piece on, and not safe for the other side.
The formula I decided on here was that each piece contributes the inverse of it’s piece value, squared. So a pawn contributes 1, a knight contributes 1/9, a queen contributes 1/81, etc. I also used one-hot features for which pieces were looking at a square. A square defended by a knight (1/9) on your side, and a rook (1/25) on your opponent’s side, has a square control value of 0.73 ((1/9)/(1/9+1/25)).
This was partially inspired by this excellent Substack article on square control in chess.
Pawn structure
Pawn structure is another one that’s pretty top-of-mind when playing a game of chess. I’m sure the model would learn these patterns eventually, but it would just act as a flat tax on the model’s compute power I think – instead of being given the data upfront it would have to waste layers finding how every pawn relates to each other.
For such simple pieces, it’s surprising how many features you end up with here. Isolated pawns, doubled pawns, backwards pawns, passed pawns, pawn chains… Pawns are complicated things.
Recency / position history
One problem with the AI the first time I really trained a decent model, was that it would opt for a draw in a totally winning position, by repeating. So you have to encode position history in the model somehow, to make sure it learns not to draw by repetition accidentally. Or conversely, to draw by repetition on purpose when losing.
I decided to implement this by marking each square that has been visited, with an exponentially decaying value. So if the square was just visited by a piece, that’s 1.0, the next turn it’s 0.5, then 0.25, etc.
This also helps the model maintain a more consistent playing style. Sometimes there’s a sacrifice available on the board, through many turns. A human would usually either decide he wants to do it or not, and stick with that decision until something concrete changes. But when I played this bot before adding recency, the bot would be ignoring the tactic for many moves then after an unrelated quiet move, go for it. It felt very alien and off-putting.
A lot of uninteresting stuff
I could talk about the hours I spent inspecting gradient norms, or methods to control exploding residuals, or Kaiming uniform initialization vs normal distributions for embeddings, or softmax-gating global embeddings and token embeddings, or multi-head query attention vs grouped query attention, or scaling embedding learning rates by the square of the model’s dimensions, or using GradNorm to balance the gradient contribution between multiple heads in multi-task learning, or figuring out multi-GPU coordination to accumulate gradients on the main device and relay those new weights to the follower devices without exploding the VRAM, or bootstrapping new models with easy predictions from previously trained models…
But in the spectrum between “entertaining blog post” and “research paper”, I opted for the former. If anyone wants to chat about this stuff, reach out! I’d love to talk shop.
The code is all open-source here, although be warned it’s pretty messy. The models themselves (221MB for the 512-dimension model, 494M for the 768-dimension model), are too large to upload to GitHub, but if anyone wants them I suppose I’ll figure out a way to share them.
Well? Did it work?
Did I manage to beat the state of the art here? Actually, yes! With the latest run, the model achieved a top-1 prediction accuracy of 55.57%! That’s over 2pp higher than the best result previously achieved, of 53.2%.
There’s a caveat here: I haven’t validated against the exact training data that Maia-2 used for its metrics. But I think if anything, I’m selecting for harder positions to predict, since I’m including blitz games, which are inherently more unpredictable.
Here’s how it performs across different skill levels:
| Skill Level | Accuracy |
|---|---|
| Beginner (≤1600) | 52.78% |
| Intermediate (1600-2000) | 55.11% |
| Advanced (2000-2300) | 56.56% |
| Expert (2300+) | 57.29% |
| Overall | 55.57% |
Anecdotally, it’s an enjoyable model to play against. It plays human-like moves, blunders like a human might, and never makes unexplainable moves.
If you play games, my PSN is mbuffett, always looking for fun people to play with.
If you're into chess, I've made a repertoire builder. It uses statistics from hundreds of millions of games at your level to find the gaps in your repertoire, and uses spaced repetition to quiz you on them.
If you want to support me, you can buy me a coffee.